
Most IT operations teams are already well-equipped to see problems.
Dashboards show infrastructure health. Monitoring tools track CPU, memory, disk, application latency, service availability, and system performance. Alerts notify teams when thresholds are crossed or unusual behavior is detected.
The visibility is there.
The harder challenge is what happens next.
After an alert fires, someone still needs to investigate the issue, collect context, check recent changes, run diagnostic commands, update a ticket, notify the right people, and decide whether remediation is required. In many organizations, that process is still manual, inconsistent, and heavily dependent on who is on call.
This is where dashboards stop — and where workflows need to begin.
VELIS, Aifa Labs’ Agentic AIOps platform, is designed to help IT teams move beyond visibility by turning operational signals into structured, repeatable, and governed workflows.

TL;DR
Dashboards help IT teams detect problems, but they rarely close the gap between alert and action. After an issue is identified, teams still need to investigate, collect context, update tickets, notify the right people, and decide whether remediation is needed. VELIS helps turn operational signals into structured, governed workflows so IT teams can respond with more consistency, better context, and clearer control.
Dashboards Are Essential, But They Are Not the Full Response
Dashboards and monitoring platforms are critical to modern IT operations. They help teams understand what is happening across infrastructure, applications, services, and environments.
Without visibility, teams are reactive. They discover problems through user complaints, delayed escalations, or business impact.
But visibility alone does not resolve incidents.
A dashboard can show that CPU utilization is high. It can show that disk usage is increasing. It can show that a service is unavailable or that response time has degraded. What it does not do by itself is determine the next operational step.
It does not automatically collect all relevant context.
It does not confirm whether a recent change caused the issue.
It does not update the incident ticket with useful diagnostic data.
It does not notify the correct team with a clear summary.
It does not decide whether remediation requires approval.
That work usually happens after the alert — and that is where IT teams spend a significant amount of time.
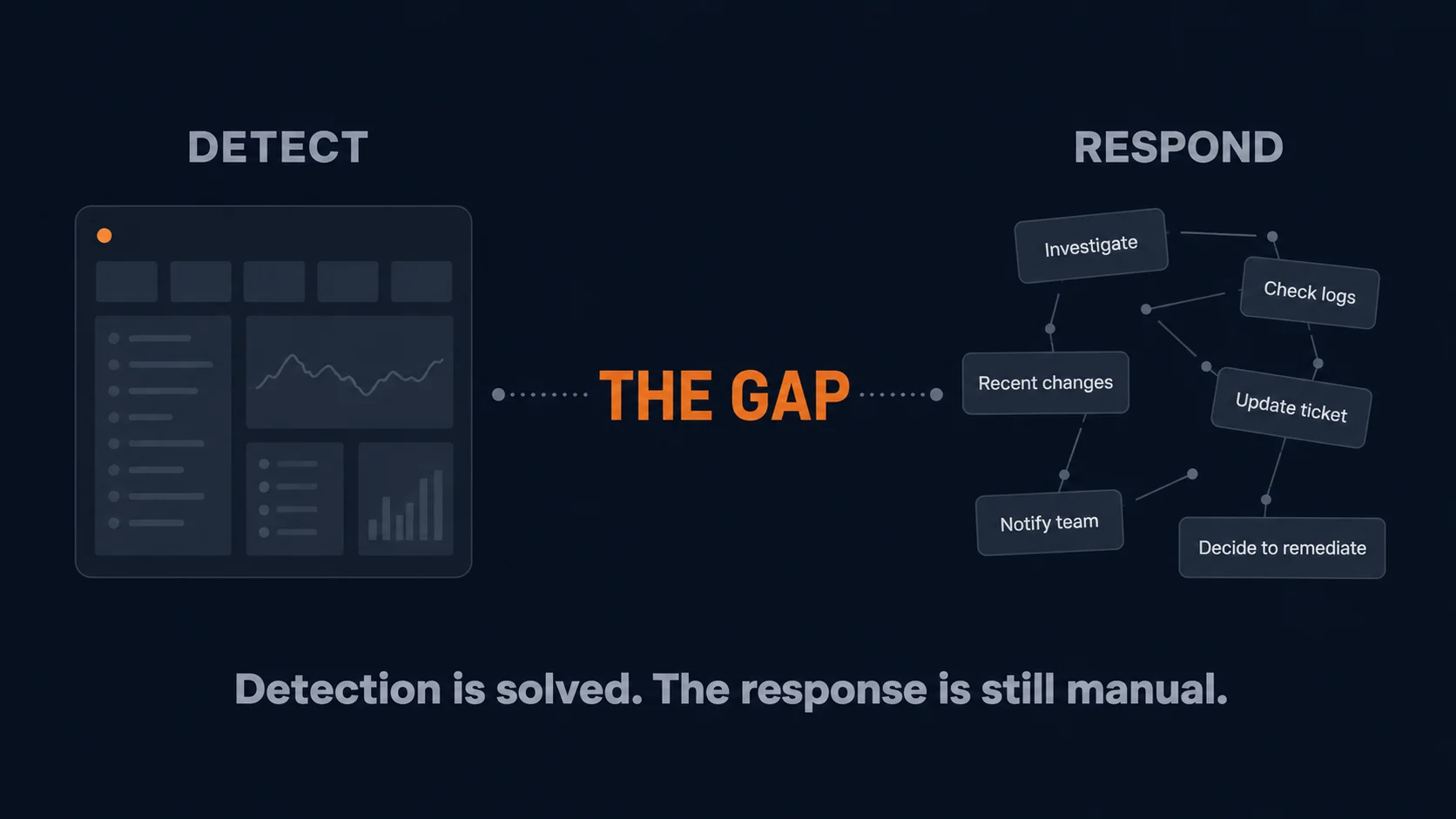
The Operational Gap After an Alert
When an alert fires, the response often looks familiar.
An engineer receives a notification, opens the dashboard, confirms the issue, logs into the affected system, checks logs, reviews recent activity, runs commands, compares the situation against a runbook, opens or updates a ticket, posts in a collaboration channel, and decides whether to escalate.
This is routine operational work. It is also where inconsistency enters the process.
One engineer may check recent deployments first. Another may begin with system logs. A senior engineer may know exactly which command to run, while a newer team member may need to search through documentation. Some tickets may include detailed diagnostic data. Others may only contain a short summary written after the fact.
The result is not necessarily poor operations. It is an uneven operation.
The same category of incident can be handled differently depending on the person, the time of day, the quality of the runbook, and the pressure of the moment. When teams are busy, steps get skipped. When documentation is outdated, knowledge stays in people’s heads. When incidents repeat, teams often restart the same investigation from scratch.
This is the alert-to-action gap: the space between detecting a problem and executing a consistent, documented response.
From Signals to Workflows
The next step for IT operations is not replacing dashboards. It is connecting dashboards and operational signals to workflows.
An alert should not only tell a team that something happened. It should be able to initiate the first steps of the response process.
That may include collecting system data, running diagnostic scripts, checking recent changes, opening or updating a ticket, notifying the right team, or routing an action for approval.
This does not remove human judgment from operations. It gives engineers better context before they make decisions.
Instead of asking an engineer to start from a blank screen every time an alert fires, a workflow can prepare the investigation, document the findings, and guide the response through predefined steps. The engineer remains in control, but the process becomes more consistent.
That is the shift VELIS supports: turning operational insights into action through workflows that are structured, repeatable, and governed.
A Practical Example: CPU Alert Response
Consider a common scenario.
A server crosses a defined CPU utilization threshold. The monitoring tool detects the spike and generates an alert.
In a traditional response, an engineer receives the alert and starts investigating manually. They may connect to the server, check active processes, review memory usage, inspect logs, look for recent deployments, update a ticket, and notify the infrastructure team.
With VELIS, that same alert can become the trigger for a workflow.
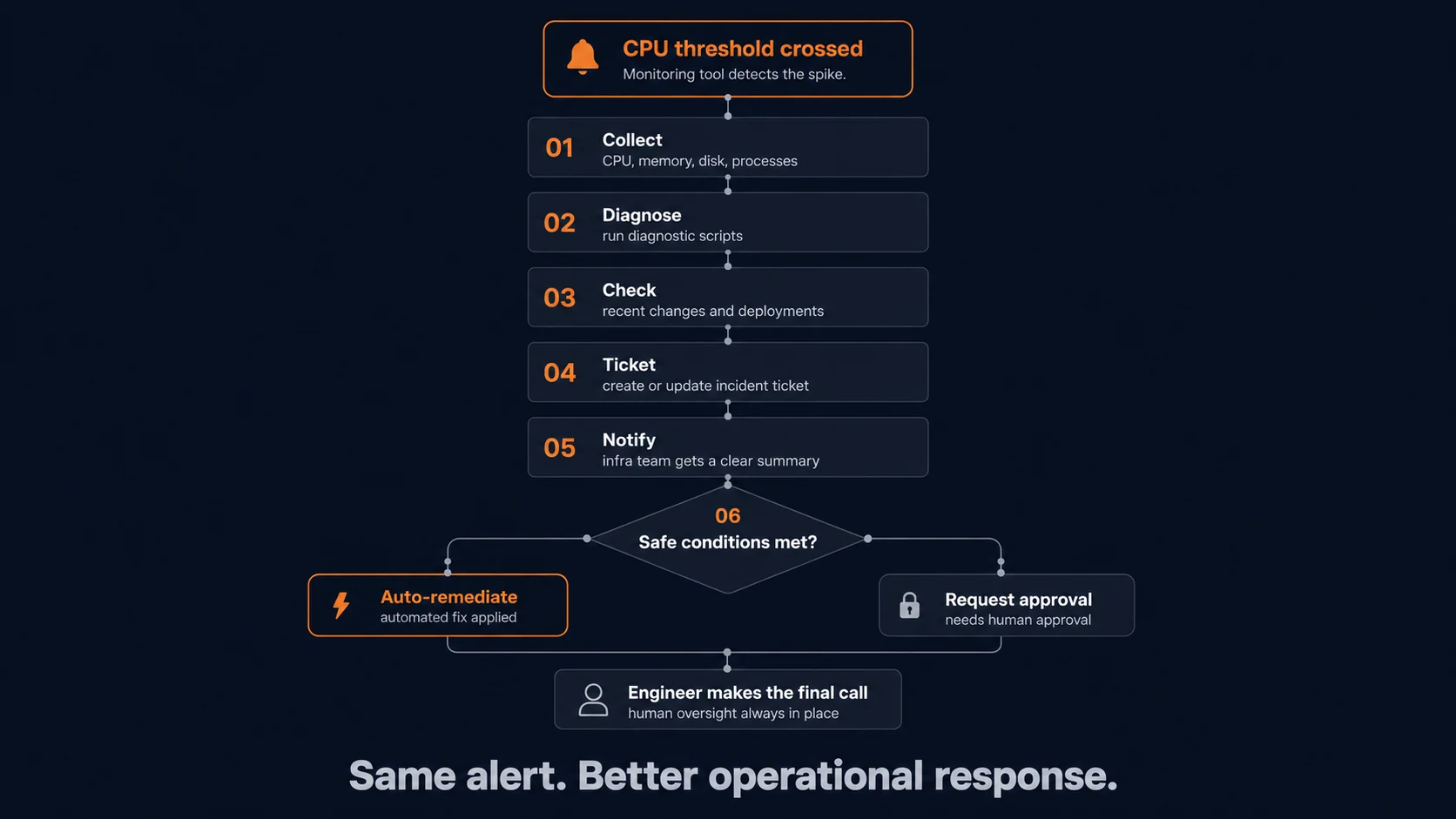
The workflow can collect CPU, memory, disk, and active process data from the affected host. It can run predefined diagnostic scripts. It can check for recent changes, deployments, or configuration updates. It can create or update the incident ticket with the collected information. It can notify the infrastructure team with a clear summary of what was found.
If predefined safe conditions are met, the workflow may execute a remediation step. If the action carries more risk, it can request approval before proceeding.
The difference is not just speed. It is consistency.
The engineer still reviews the situation and makes the final call where needed. But they are no longer starting from zero. They have the relevant context, the ticket is already updated, the right team has been notified, and the response has followed a defined process.
Same alert. Better operational response.
Why Governance Matters in IT Automation
Automation in IT operations must be handled carefully.
For some tasks, automatic execution may be appropriate. For others, human approval is required. Restarting a non-critical service under defined conditions is very different from making a production change, disabling access, or modifying infrastructure configuration.
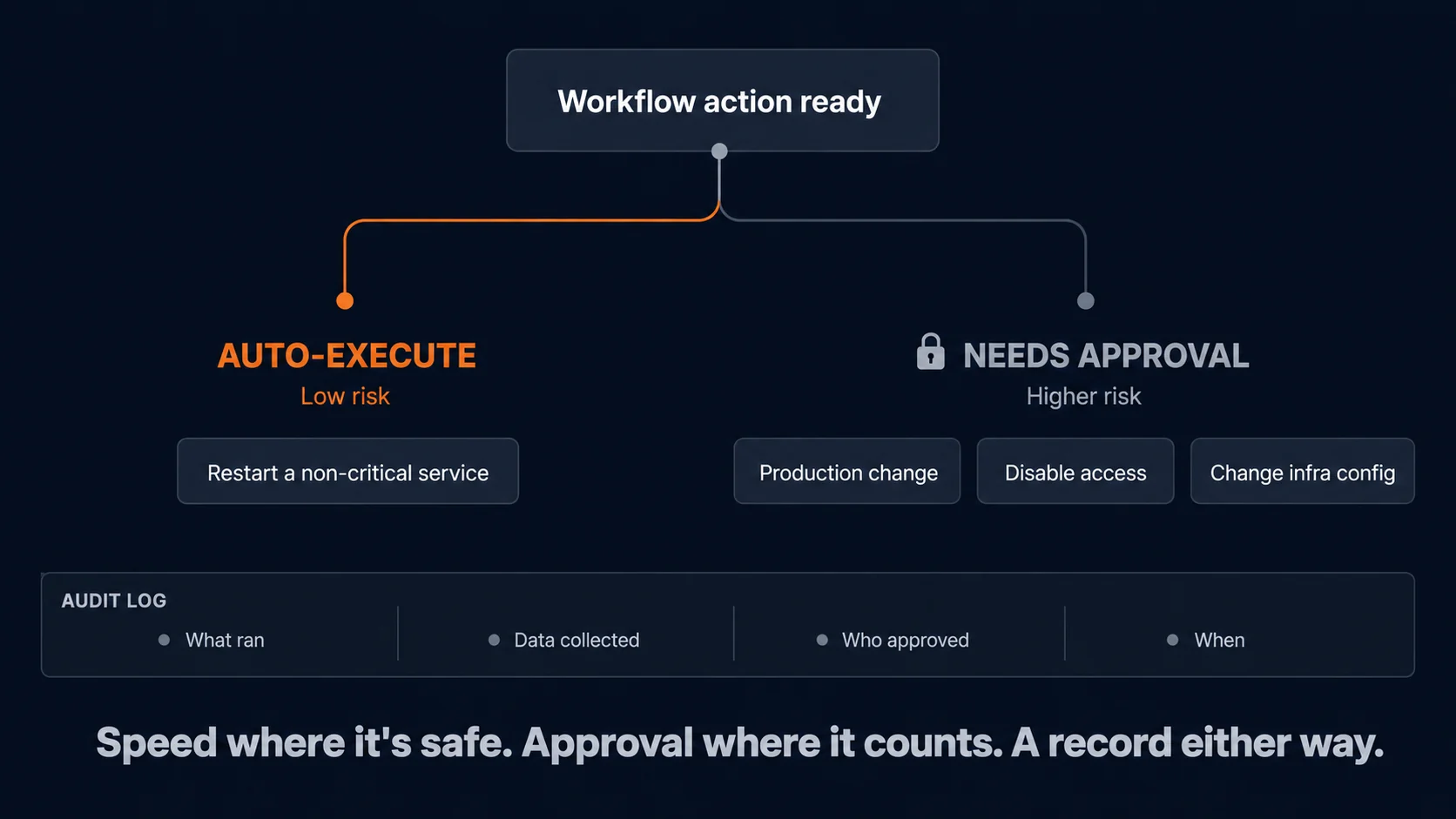
This is why governance is not optional.
A mature workflow should support approval gates, role-based control, logging, and clear execution history. Teams need to know what was triggered, what data was collected, what action was taken, who approved it, and when it happened.
This is especially important in enterprise environments where operations teams need to balance speed with control.
A workflow with an approval step can be faster and safer than informal coordination. Instead of asking for approval through scattered messages, the workflow can present the relevant context, request a decision, and keep a record of the outcome.
That creates a more reliable process for both operations and auditability.
How VELIS Helps Teams Act on Operational Insights
VELIS helps bridge the gap between visibility and execution.
Rather than replacing existing monitoring tools, VELIS can work as an operational layer that helps teams act on the signals those tools already generate.
With VELIS, an operational signal can trigger a workflow that may:
 Collect system and application data
Collect system and application data
 Run diagnostic scripts
Run diagnostic scripts
 Check recent changes
Check recent changes
 Open or update tickets
Open or update tickets
 Notify the correct team
Notify the correct team
 Execute predefined remediation steps
Execute predefined remediation steps
 Request approval when needed
Request approval when needed
 Maintain logs and governance around the actions taken
Maintain logs and governance around the actions taken
This helps teams move from ad hoc response to structured execution.
For IT operations teams, that means less time repeating the same investigation steps. For managers, it means more consistent processes and better visibility into what happened. For business stakeholders, it means faster response and reduced operational friction.
Most importantly, it helps standardize operational knowledge.
Instead of relying only on individual experience or tribal knowledge, teams can encode known response patterns into workflows. New team members can follow a consistent process. Senior engineers can spend less time on repetitive tasks. Incidents can be handled with more context and less guesswork.
The Goal Is Not More Automation. It Is Better Operations.
AIOps should not be measured only by how many alerts it can generate or how many dashboards it can display.
The real value comes when insights lead to action.
Dashboards help teams understand what is happening. Workflows help teams respond in a structured way. Governance makes sure those responses remain controlled, visible, and auditable.
That combination is what helps IT operations mature beyond reactive monitoring.
VELIS brings these elements together by helping teams turn operational signals into workflows that collect context, coordinate response, support approvals, and execute defined actions when appropriate.
The takeaway is simple:
Seeing the problem is only the first step.
The next advantage is knowing what should happen next — and making that process repeatable.


