
Enterprise infrastructure teams in 2026 operate under a paradox: the systems designed to give them visibility often bury them in noise. Thousands of alerts fire simultaneously across servers, network devices, and application stacks, each one technically valid, most of them operationally irrelevant in isolation. The result is an inflated “Mean Time to Repair” (MTTR) that compounds into real business losses, service degradation, erode stakeholder trust, and engineering hours burned on triage instead of resolution.
VELIS was built to solve this problem at its root. As an on-premises AIOps platform powered by autonomous agents, VELIS does not route your critical infrastructure data through the cloud. Instead, it deploys lightweight agents on your servers, correlates signals in real time within your environment, and surfaces actionable intelligence, so your teams spend their time fixing problems, not finding them.

Why MTTR is the metric that matters most for Infrastructure Teams
Mean Time to Repair, the average duration from incident detection to full-service restoration, is one of the most direct indications of operational health. For Systems Administrators managing critical infrastructure, it captures the friction embedded in their day-to-day reality: time spent triaging ambiguous alerts, correlating disconnected signals, escalating to the right person, and confirming resolution.
An elevated MTTR has cascading consequences:
- Service disruption compounds over time, turning five-minute fault into a thirty-minute outage.
- Incident fatigue accumulates on the team, degrading response quality on future events.
- Leadership loses confidence in infrastructure reliability, slowing organizational momentum.
- Budget conversations shift toward reactive spending rather than strategic investments.
The formula is simple: Total Repair Time divided by Number of Incidents. What is not simple is driving that number down without investing years in manual tooling and process redesign. That is precisely where VELIS creates leverage.
The Alert overload Problem in enterprise environments
Modern enterprise infrastructure is instrumented deeply. Every virtual machine, network device, database cluster, and application layer emits events continuously. In a mid-sized enterprise, this translates to hundreds of thousands of events per day, many of them legitimate, few of them requiring immediate human attention.

The problem is not lack of data. The problem is that traditional monitoring tools were not designed to reason about data, they were designed to emit it. Every threshold breach generates an alert. Every alert demands attention. The cumulative effect is alert fatigue: a state in which responders become desensitized to notification, critical events get lost among routine ones, and triage becomes a guessing game.
For enterprises with strict security and data sovereignty requirements, this challenge is amplified. Cloud-based aggregation tools are not viable options when critical infrastructure metadata cannot leave the perimeter. Teams are left managing noise manually, inside the walls they cannot lower.
VELIS addressed this at the architectural level. Because its agents operate within your environment, on your servers, behind your firewall, they can observe, correlate, and act on data that never needs to travel outside your perimeter.
Agentic Correlation: from raw signals to root cause
The core of the VELIS approach is what we call agentic correlation, a fundamentally different paradigm from rule-based alerting. Rather than waiting for humans to connect the dots between related events, VELIS agents continuously analyze telemetry streams in real time, identify causal relationships between signals, and construct a unified incident picture before the first responder is even paged.
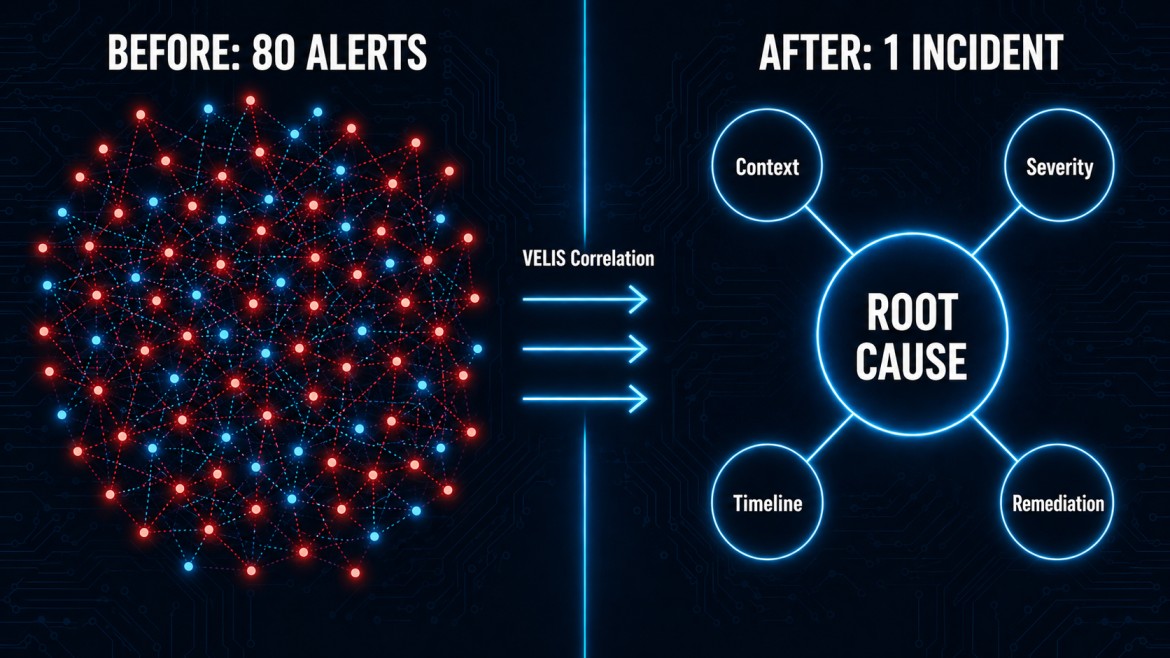
Where a traditional monitoring stack might surface forty separate alerts from a single underlying configuration drift, VELIS collapses those forty into one correlated incident, annotated with context, ranked by severity, and enriched with the information your team needs to act immediately.
How VELIS reduce MTTR in practice
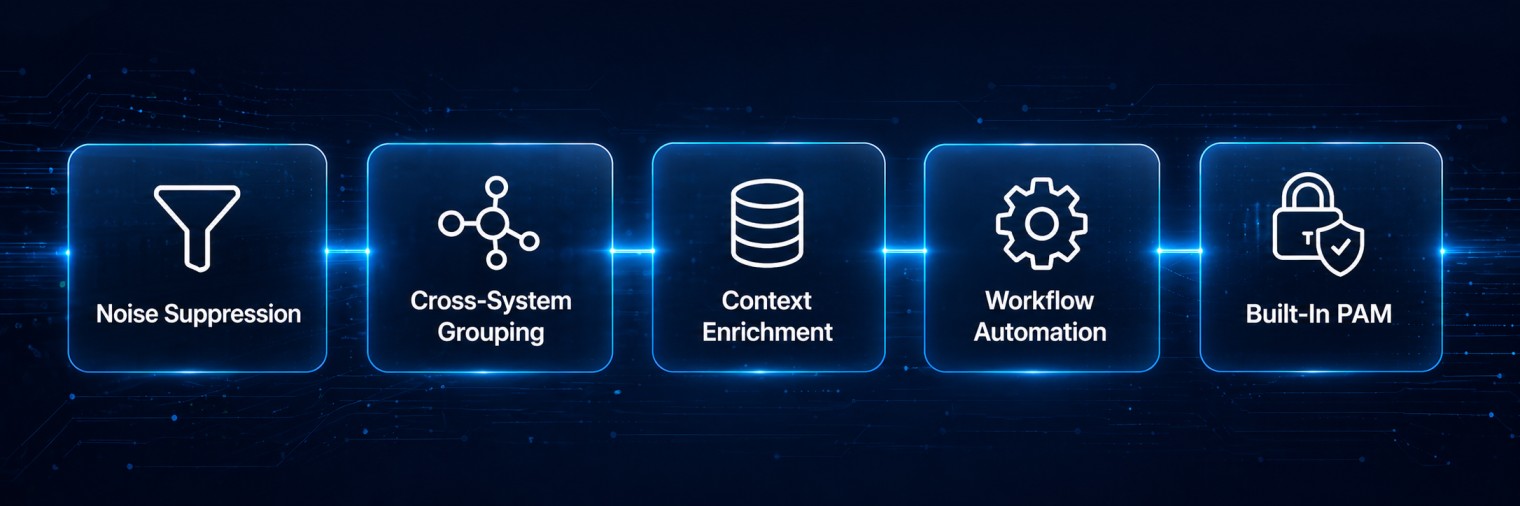
Intelligent Noise Suppression
VELIS agents learn the baseline behavior of your infrastructure over time. Transient spikes, known flapping services, and repetitive low-severity events are automatically suppressed before they reach your team. The result is a dramatic reduction in alert volume, without any reduction in coverage. Your team sees less, and acts on more.
Cross-System Event Grouping
Incidents rarely have a single source. VELIS agents correlate events across systems, linking a database latency spike to a concurrent CPU saturation event and an upstream deployment, into a single, coherent incident thread. This eliminates the scenario where three responders independently investigate three symptoms of the same root cause.
Automated Context Enrichment
Every correlated incident surfaced by VELIS arrives pre-enriched. Agents automatically attach relevant system state, recent configuration changes, historical incident data, and suggested remediation paths — drawing from your environment, not generic external databases. Responders arrive at an incident with context, not questions.
No-Code Workflow Automation
Through VELIS’s no-code workflow module, teams can define automated response actions that trigger the moment a correlated incident is detected — running diagnostic scripts, isolating affected components, notifying the right stakeholders, or initiating auto-remediation for known failure patterns. The manual first-response steps that historically consumed the first 15 minutes of every incident are replaced by autonomous action.
Privilege Access Management Built In
VELIS’s Intelligent PAM module ensures that automated and manual remediation actions are executed under the right access controls. Credential management, session recording, and least-privilege enforcement happen natively within the platform — so speed of resolution never comes at the cost of security posture.
Visibility that connects teams and leadership
Reducing MTTR is not just an operational achievement, it is a business outcome that needs to be visible at every level of the organization. VELIS’s unified visibility module bridges the gap between the Systems Administrator resolving an incident at 2 a.m. and the VP reviewing operational health the following Monday morning.
For infrastructure teams, VELIS provides a real-time operational console: live incident timelines, agent status across the estate, correlation maps showing which signals contributed to which incidents, and workflow execution logs. The complexity of your environment becomes navigable.
For VPs and senior stakeholders, VELIS delivers executive-level reporting with no configuration overhead. Within 30 days of deployment, leadership has access to concrete, trend-based data: alert volume reduction, MTTR before and after, incidents resolved autonomously versus manually, and the business hours recovered from reduced downtime. The improvement is not anecdotal — it is measured, timestamped, and audit-ready.
This alignment between operational and executive visibility is what converts VELIS from a tool into a strategic infrastructure decision.
On-premises by design, security without compromise
For enterprises operating in regulated industries or managing classified and sensitive infrastructure, the idea of routing operational telemetry through a third-party cloud is simply not an option. VELIS was designed from the ground up with this constraint as a first principle, not an afterthought.
The VELIS architecture is straightforward by intent:
- Lightweight agents are installed on your servers and communicate exclusively with the VELIS platform hosted within your environment.
- No telemetry, metadata, or operational data traverses external networks.
- All correlation, enrichment, and automation runs inside your perimeter.
- Compliance and audit requirements are met without sacrificing platform capability.
You get the full power of an AI-driven AIOps platform with the data governance posture your organization demands.
Operational excellence starts on day one
In enterprise infrastructure, complexity is not going to decrease. The number of systems, services, and signals your team manages will only grow. The organizations that maintain operational excellence in this environment will not be the ones that hire more responders — they will be the ones that deploy smarter systems.
VELIS gives your Systems Administrators the intelligence layer they need to move faster, with more confidence, and with full awareness of what is happening across the estate. It gives your VPs the evidence they need to demonstrate infrastructure ROI within a single month of deployment.
The technology is agentic. The deployment is on-premises. The results are measurable.


