
Agentic correlation and noise suppression in modern infrastructure
MTTR (mean time to repair) is one of the most closely watched metrics in enterprise IT operations, and one of the hardest to move without rethinking how incidents are detected, correlated, and resolved. This article explains how AI-driven noise suppression, cross-system event grouping, and workflow automation are helping infrastructure teams materially reduce MTTR, including how on-premise AIOps platforms address the specific constraints of regulated industries. It is especially relevant for heads of IT operations, SRE leads, and VP Infrastructure. Anyone whose team is measured on reliability, IT incident response time, and operational efficiency. By the end, readers will understand what drives MTTR up, what drives it down, and what governed, on-premise AI operations actually look like in practice.

The Visibility Paradox Driving MTTR Higher
Enterprise infrastructure teams in 2026 operate under a paradox: the systems designed to give them visibility often bury them in noise. Thousands of alerts fire simultaneously across servers, network devices, and application stacks, each technically valid, but most operationally irrelevant in isolation.
The result is an inflated “Mean Time to Repair” (MTTR) that compounds into real business losses, service degradation, eroded stakeholder trust, and engineering hours burned on triage instead of resolution.
Some AIOps platforms are now shifting from simply collecting data to interpreting and acting on it in real time, reducing the burden on infrastructure teams.
Why MTTR Matters for Enterprise Infrastructure Teams
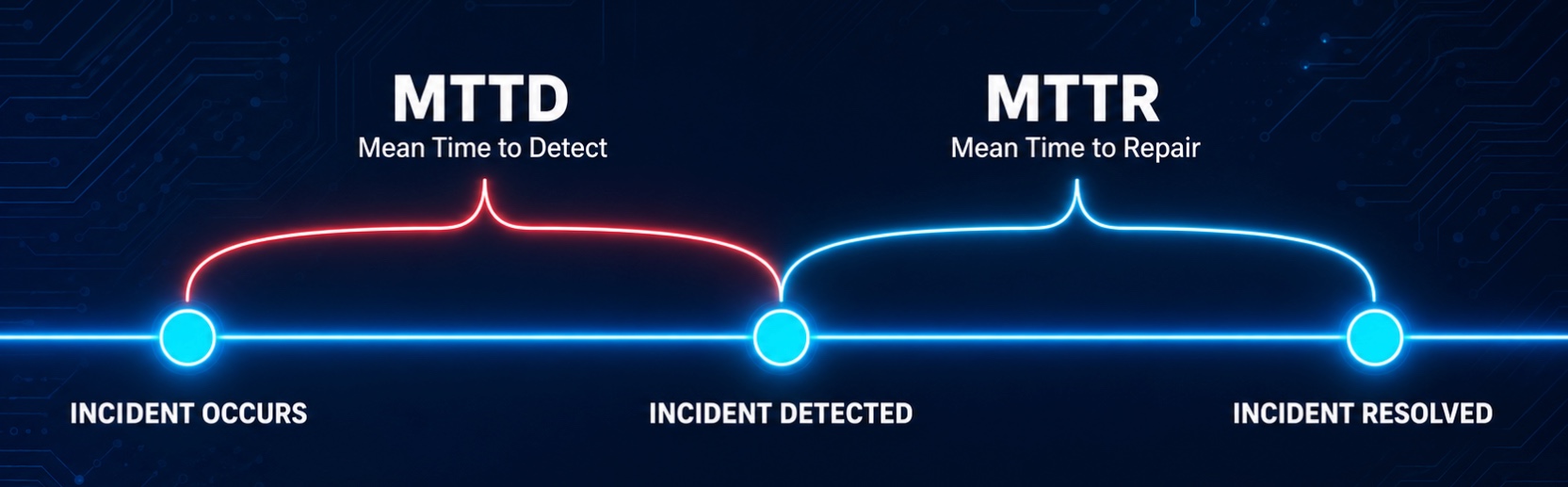
Mean Time to Repair measures how long it takes to go from detecting a problem to fixing it. It is one of the clearest signals of operational health.
For systems administrators managing critical infrastructure, MTTR captures the full arc of IT incident response time, the friction embedded in their day-to-day reality: time spent triaging ambiguous alerts, correlating disconnected signals, escalating to the right person, and confirming resolution.
An elevated MTTR has cascading consequences:
- Service disruption compounds over time, turning a five-minute fault into a thirty-minute outage.
- Incident fatigue accumulates on the team, degrading response quality on future events.
- Leadership loses confidence in infrastructure reliability, slowing organisational momentum.
- Budget conversations shift toward reactive spending rather than strategic investment.
The formula is simple: Total Repair Time divided by Number of Incidents. What is not simple is driving that number down without investing years in manual tooling and process redesign. That is precisely where modern AIOps approaches create leverage.
It is worth distinguishing MTTR from a closely related metric: MTTD, or Mean Time to Detect. MTTD measures how long it takes to identify that a problem exists. MTTR measures how long it takes to fix it once identified. Both are degraded by the same root cause — alert noise and poor signal correlation, and both improve when an intelligence layer is applied earlier in the incident lifecycle. Reducing MTTD compresses the window before damage compounds; reducing MTTR limits the damage once an incident is confirmed. In practice, teams that address one without the other rarely sustain meaningful operational improvement.
The Alert Overload Problem in Enterprise Environments
The problem is not lack of data. The problem is that traditional monitoring tools were not designed to reason about data; they were designed to emit it.
Modern enterprise infrastructure is instrumented deeply. Every virtual machine, network device, database cluster, and application layer emits events continuously. In a mid-sized enterprise, this translates to hundreds of thousands of events per day, many of them legitimate, few of them requiring immediate human attention.

Every threshold breach generates an alert. Every alert demands attention. The cumulative effect is alert fatigue: a state in which responders become desensitised to notifications, critical events get lost among routine ones, and triage becomes a guessing game.
For enterprises with strict security and data sovereignty requirements, the challenge is harder. Cloud-based aggregation tools are not viable options when critical infrastructure metadata cannot leave the perimeter. Teams are left managing noise manually, which is precisely why on-premise AIOps has become a critical requirement for regulated industries.
What This Looks Like in Practice
One of our life sciences customers, managing a complex ERP environment, was handling over 20,000 infrastructure changes annually, many of them manual or semi-automated. This led to frequent human errors, operational risk, and unplanned downtime.
After implementing an agent-driven automation and control layer:
- 60% of change processes were automated
- 40,000+ hours saved annually (~20 FTEs)
- Accidental execution of privileged commands was eliminated
- Compliance and audit readiness improved significantly

Most importantly, IT incident response became faster and more predictable, helping reduce MTTR by up to 50% by eliminating triage time and accelerating root cause identification. These improvements are not incidental; they are driven by a shift in how incidents are detected, grouped, and resolved.
Full case study available on request.
How MTTR Is Reduced
The following four capabilities are how modern AIOps platforms reduce MTTR consistently across enterprise environments — without adding headcount or replacing existing tooling wholesale.
Intelligent Noise Suppression
Systems learn baseline behaviour and suppress repetitive or low-value alerts, reducing noise without losing visibility. Responders see fewer alerts overall, and the ones they do see carry higher signal value.
Cross-System Event Grouping
Related signals across infrastructure layers are grouped into a single incident, avoiding duplicated effort across teams. A network degradation, an application timeout, and a database spike that share the same root cause become one incident — not three.
Context Enrichment
Incidents are enriched with relevant system data, recent changes, and historical patterns, so responders start with context, not guesswork. The first minutes of triage — typically the most expensive part of IT incident response time — are compressed before a human ever opens the ticket.
Workflow Automation
Common response actions — diagnostics, routing, or remediation — can be triggered automatically, eliminating the first 10–15 minutes of manual effort in every incident. Over time, the platform learns which automated actions resolve which classes of incident, compounding the MTTR reduction.
Visibility That Connects Teams and Leadership
Reducing MTTR is not just an operational metric. It is a business outcome.
Infrastructure teams need real-time visibility into incidents and system health. Leadership needs trend-level insights they can act on. When those two views are disconnected, operational improvements stay invisible to the people who fund them.
The metrics that bridge this gap include:
- Alert volume reduction
- MTTR improvement over rolling periods
- Automation impact by incident category
- Downtime avoided and estimated cost of prevention
Bridging this gap is what turns operational improvements into measurable business value and what transforms MTTR from an engineering KPI into a board-level reliability signal.
On Premises by Design: Security Without Compromise
For enterprises operating in regulated industries or managing classified and sensitive infrastructure, routing operational telemetry through a third-party cloud is simply not an option.
For these enterprises, AiFA Labs built VELIS: an agentic AIOps platform designed to deliver intelligent correlation, enrichment, and automated remediation entirely on-premise.
VELIS was built with this constraint as a first principle, enabling teams to adopt AI-driven operations without compromising data residency or control.
The architecture is intentionally straightforward:
- Lightweight agents are installed on your servers and communicate exclusively with the VELIS platform hosted within your environment.
- No telemetry, metadata, or operational data leaves your network.
- All correlation, enrichment, and automation run inside your perimeter.
- Compliance and audit requirements are met without sacrificing platform capability.
The result is an on-premise AIOps system that delivers intelligence and automation while aligning fully with enterprise security and governance requirements.

Operational Excellence Starts on Day One
In enterprise infrastructure, complexity is not going to decrease. The number of systems, services, and signals your team manages will only grow.
The organisations that maintain operational excellence in this environment will not be the ones that hire more responders. They will be the ones that deploy systems that reduce noise, surface context, and automate response.
This is the architecture VELIS was built around.
It gives systems administrators the intelligence layer they need to move faster, with more confidence, and full awareness of what is happening across the estate. For leadership, it provides clear, measurable improvements in MTTR, incident volume, and operational efficiency, often within the first few weeks of deployment.
The technology is agentic.
The deployment is on premises.
The outcome is faster resolution, with a measurable impact on MTTR.
Frequently Asked Questions
What is MTTR?
MTTR, or mean time to repair, is a core IT operations metric that measures the average time elapsed between the detection of an incident and its full resolution. It is calculated by dividing total repair time by the number of incidents over a given period. For enterprise infrastructure teams, MTTR reflects the combined friction of triage, escalation, diagnosis, and remediation, making it a reliable indicator of how well a team’s tools, processes, and workflows are performing under real operational conditions.
How is MTTR calculated?
MTTR is calculated by dividing the total time spent resolving incidents by the total number of incidents resolved within the same time window. For example, if a team resolves ten incidents in a month and the cumulative resolution time is 500 minutes, the MTTR is 50 minutes. What makes MTTR difficult to reduce in practice is that the formula is simple but the variables driving it are not: alert noise, poor correlation, manual triage steps, and slow escalation paths all inflate the number invisibly.
What is mean time to repair and how is it different from MTTD?
Mean time to repair measures how long it takes to resolve an incident once it has been identified. Mean time to detect (MTTD) measures how long it takes to identify that an incident is occurring in the first place. Both metrics are degraded by the same underlying problem, alert noise and poor signal correlation, and both improve when AI-driven event grouping and context enrichment are applied earlier in the incident lifecycle. Enterprises that address only one of the two rarely sustain meaningful operational improvement.
How to reduce MTTR in enterprise IT operations?
MTTR is reduced by eliminating the manual work that inflates it: noisy alerts that demand human triage, disconnected signals that require cross-team coordination, and remediation steps that rely on responders executing the same runbooks repeatedly. The most effective approaches combine intelligent noise suppression, cross-system event correlation, automated context enrichment, and workflow automation that triggers diagnostic and remediation actions without waiting for human initiation. Platforms like VELIS apply these capabilities as a governed, on-premise system, meaning infrastructure teams gain the speed benefits of AI-driven operations without compromising data sovereignty or compliance requirements.
What is the difference between AIOps and traditional monitoring?
Traditional monitoring tools are designed to collect and surface data. They emit alerts when thresholds are breached and leave the interpretation to the responder. AIOps platforms go further: they analyse events across systems in real time, suppress redundant alerts, group related signals into a single correlated incident, enrich that incident with context, and in advanced implementations, initiate automated remediation. The difference is the shift from visibility to action. Traditional monitoring tells a team that something is wrong. AIOps tells them what is wrong, why — and in some cases resolves it before a human intervenes.
TL;DR
- MTTR (mean time to repair) is the clearest signal of operational health in enterprise infrastructure, and it is inflated primarily by alert noise, poor correlation, and manual triage, not by the complexity of the underlying incidents.
- Traditional monitoring tools emit data. AIOps platforms interpret and act on it. That distinction is what separates a team that responds to incidents from one that resolves them faster with each iteration.
- The four levers that consistently reduce MTTR are: intelligent noise suppression, cross-system event grouping, context enrichment at the point of alert, and automated workflow execution for common response actions.
- For enterprises in regulated industries, cloud-based AIOps is not always viable. On-premise AIOps, where all correlation, enrichment, and automation runs inside the enterprise perimeter, delivers the same intelligence without compromising data sovereignty or audit readiness.
- MTTR improvements are measurable within weeks of deployment. The goal is not to hire more responders. It is to deploy systems that make the responders you already have significantly more effective.


